S’il-vous-plaît… Dessine-moi un projet
Maëlle Salmon 🏠 https://masalmon.eu 🐦 ma_salmon
Licence CC-BY-SA
👋 Bonjour depuis Nancy !

Picture by Dimitry Anikin on Pexels.
Gérer votre projet R
Je vais partager des astuces et outils !

Picture by cottonbro on Pexels.
Mais d’abord, qui suis-je ?
Projets récents
Diverses missions pour rOpenSci, notamment maintenance du package dev guide. 🔧
Travail sur la prochaine version de pkgdown. ✨
Livre “HTTP testing in R” avec Scott Chamberlain. 📖
Cours “Scientific Rmd blogging”. 📝
Engagements actuels dans R
Compte Twitter de R-Ladies Global. 🐦
Éditrice pour le système de revue de paquets de rOpenSci. 📦
Diverses présentations de partage de connaissances. 😉
Retrouvez les diapos en ligne 😁
Objectifs de ma présentation
Que chacun·e apprenne au moins une chose nouvelle. 😁
⚒️ Principes de base pour les projets R ;
⚒️ Comment protéger votre projet des changements extérieurs ;
⚒️ Comment structurer votre projet ;
⚒️ Comment faire tourner votre projet.
Pourquoi des conseils sur les projets ?
😿 Pas demandé par le Petit Prince.
😺 Améliorer la vie de toute personne touchant à ou lisant vos résultats et leur origine. Reproducibilité.
😹 Toujours de quoi s’améliorer ou procrastiner.
Pourquoi m’écouter moi sur ce sujet ?
😦 Pas régulièrement en charge d’analyses.
😄 Assez au courant des nouveautés de R.
Quelques bases

Picture by cottonbro on Pexels.
Ma source principale de conseils : Jenny Bryan !
“Everything I know is from @JennyBryan.” —@sharlagelfand #mood #rstudioconf
— Kara Woo (@kara_woo) January 30, 2020
Aparté, la présentation de Sharla Gelfand
Don’t repeat yourself, talk to yourself! Repeated reporting in the R universe
Sharla est aussi une excellente source de bonnes idées ! 💐
Ma source principale de conseils : Jenny Bryan !

Logo par Martin Monkman.
Votre projet, un jardin ?

Picture by Irina Iriser on Pexels.
Oui, mais une unité indépendante !
Un projet, un dossier !
The Kei-tora Gardening Contest is an annual event put on by the Japan Federation of Landscape Contractors to see who can build the best looking garden on the back of a Kei truck. Here are some of the winners from the past 12 years. https://t.co/IpkRiALn7a pic.twitter.com/vep4K0VZt6
— Doctor Popular 💉 💉 🎉 (@DocPop) June 10, 2021
🔥
The only two things that make @JennyBryan 😤😠🤯. Instead use projects + here::here() #rstats pic.twitter.com/GwxnHePL4n
— Hadley Wickham (@hadleywickham) December 11, 2017
Les chemins par rapport à la racine du projet

Illustration par Allison Horst.
Paquet here de Kirill Müller
-
On met un fichier texte vide nommé
.hereà la racine du projet. -
Les chemins sont définis par rapport à cela.
here::here()
[1] "/home/maelle/Documents/conferences/rr2021"
here::here("data")
[1] "/home/maelle/Documents/conferences/rr2021/data"
Toujours repartir de zéro
-
Redémarrer R régulièrement et sans peur !
-
Ne JAMAIS sauver et recharger .RData !
`usethis::use_blank_slate()` sets your @rstudio preference to NEVER save/restore .RData on exit/startup, which is a lifestyle endorsed by many #rstats folks (including me).
— Jenny Bryan (@JennyBryan) June 15, 2021
Just did a clean install and got my first chance to use this on my own behalf 😌https://t.co/Qwd8VzaCVn
“Flux de travail orienté projet”
🌹 Article de blog de Jenny Bryan
🌹 Une manière de vivre, euh, travailler !
✨ usethis::create_project() ✨
Le nom de vos roses
Qu’y a-t-il dans un nom ? Ce que nous appelons rose, par n’importe quel autre nom sentirait aussi bon.
Shakespeare dans Roméo et Juliette.
Pas vrai pour écrire du code ! 😅
Nommer vos fichiers
-
Lisibles par des machines (pas d’accent)
-
Lisibles par des humains (indicatifs du contenu)
-
Vont bien avec l’ordre par défaut (AAAA-MM-JJ plus que JJ-MM-AAAA)
Votre projet au fil du temps
🌻 Sauvegardez vos fichiers ! 🌻

Picture by Skitterphoto on Pexels.
Le contrôle de version
Votre projet va évoluter, comment garder la trace des changements pour pouvoir revenir en arrière ?

Picture by PhotoMIX Company on Pexels.
Le contrôle de version
-
dates dans noms de fichiers
-
ou contrôle de version.
Apprendre git : pas simple, mais ça vaut la peine ! Pas du R mais utile pour faire du R.
Pouvoir mieux faire des essais, revenir en arrière, comprendre les changements.
git, c’est quoi ?

XKCD par Randall Munroe.
git, c’est quoi ?
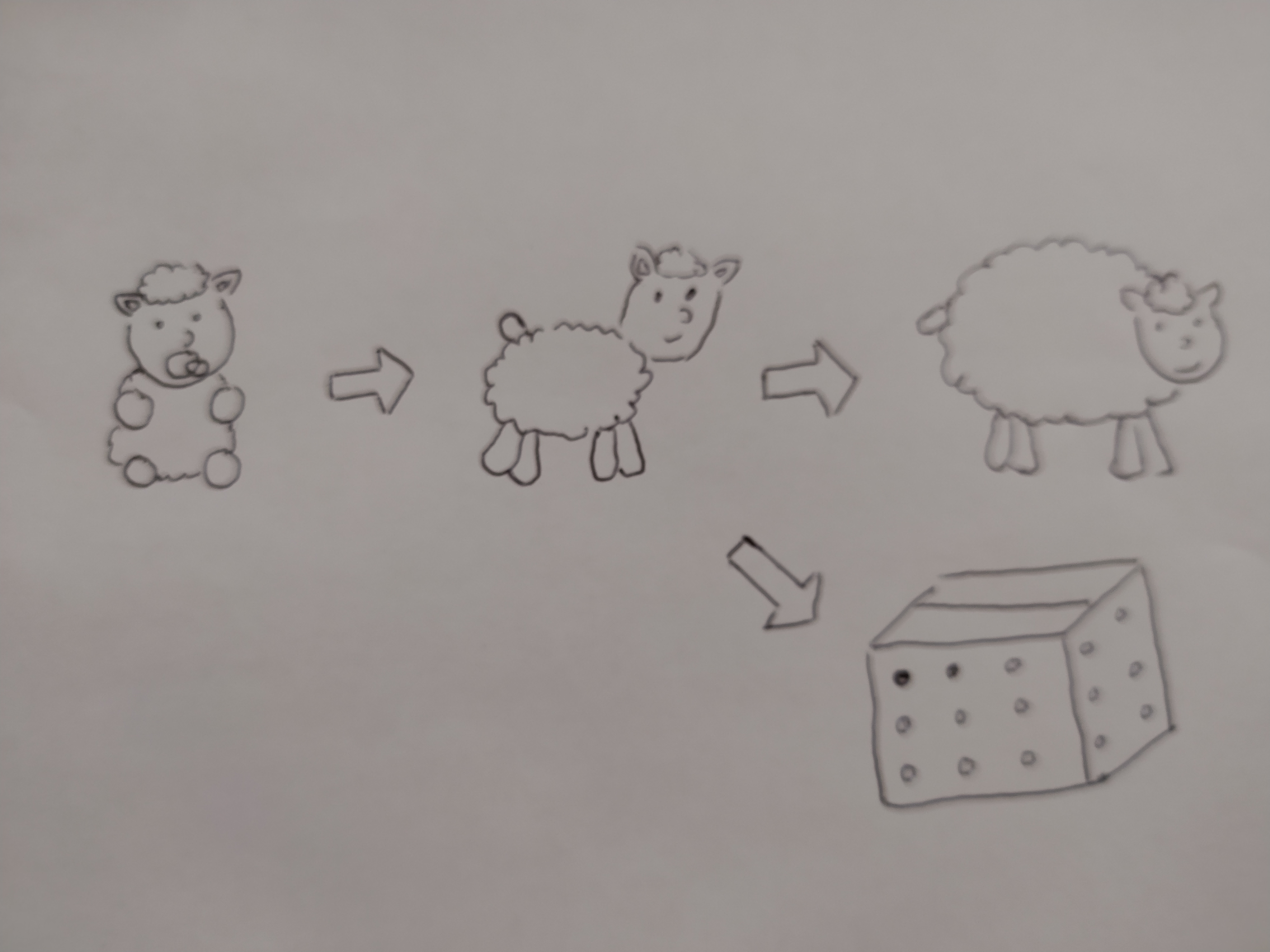
Dessin par Damien Cornu. ❤️
Quelques commandes git expliquées grosso modo
git addpour commencer à suivre un fichier (.gitignorepour lister les fichiers à ignorer) ;
git commitpour enregistrer un changement dans l’historique ;
git pull/git pushpour télécharger / publier la version locale dans la version distante (sur GitHub ?);
git checkout -bpour créer une “branche.”
Où écrire les commandes git ?
Mes préférences 😁
- Paquets usethis (
usethis::use_git(),usethis::use_github(), etc.) et gert (gert::git_push()) pour ne pas quitter R ;
- Fenêtre git de RStudio pour cliquer et ne pas aller trop loin de R ;
- Ligne de commande pour les commandes copiées collées depuis Stack Overflow ;
- Une interface graphique pour mieux visualiser ? Par exemple GitKraken, VSCODE.
Ressources sur git
-
Excuse Me, Do You Have a Moment to Talk About Version Control?, Jenny Bryan.
-
Happy Git and GitHub for the useR, Jenny Bryan, the STAT 545 TAs, Jim Hester.
-
Reflections on 4 months of GitHub: my advice to beginners, Suzan Baert.
Jusqu’ici, ce que nous savons de Jenny Bryan…
-
Isoler les projets, redémarrer R régulièrement.
-
Bien nommer ses fichiers.
-
Utiliser le contrôle de version.
Plus de sagesse de Jenny Bryan et al
🌹 Good enough practices in scientific computing Wilson G, Bryan J, Cranston K, Kitzes J, Nederbragt L, et al. (2017) Good enough practices in scientific computing. PLOS Computational Biology 13(6): e1005510. https://doi.org/10.1371/journal.pcbi.1005510
🌹 What They Forgot to Teach You About R, Jenny Bryan, Jim Hester.
Protéger votre projet des changements extérieurs

Picture by cottonbro on Pexels.
Petit scénario catastrophe…
-
Vous faites une belle manipulation de données avec
paquet::ma_fonction_favorite()… -
Et un peu plus tard cette fonction disparaît du paquet.
Pour de bonnes raisons mais votre script est-il cassé ? 😱
Stocker les dépendances du projet
Encapsuler votre projet ! 🎉
Outil indispensable : renv de Kevin Ushey !
Successeur de packrat.
renv en trois pas
-
renv::init() -
On installe et enlève des paquets 🎵 comme d’habitude 🎵. Régulièrement
renv::snapshot(). Métadonnées des dépendances automatiquement stockées dans le fichierrenv.lock. 🔒 -
Votre collègue qui hérite du projet fait
renv::restore().
Encore plus d’encapsulage
🐳 Docker ? 🔒 Version de R, système opératoire, tout quoi.
Là, il faut lire tout ce qu’a écrit Colin Fay. 👋 Colin !
Protéger votre projet des changements extérieurs
Bien lister les dépendances du projet.
Le plus simple pour commencer, adopter renv.
Mais quelle structure de projet ?

Picture by cottonbro on Pexels.
Quoi dans le projet ?
-
Des données ou comment les obtenir,
-
Du code (pas dupliqué, en fonctions),
-
Des résultats dans un rapport, des tableaux, figures…
Quelle structure pour le projet ?
-
Toujours la même.
-
Création automatisable.
-
… Paquet ou pas ?
projectTemplate
By Kenton White.
Love for ProjectTemplate, Hilary Parker:
✅ “La routine est votre amie.”
✅ “Il est plus simple de customiser quelque chose qui existe que de commencer de rien.”
✅ “La reproducibilité doit être la plus facile possible.”
✅ “Trouver des choses doit être aussi facile que possible.”
Faire un paquet R ?
- Pour stocker des fonctions et données utilisées dans plusieurs projets : OUI !!!
Pour réduire ses craintes, il faut se dire que ce n’est ni plus ni moins qu’un dossier organisé d’une manière contrainte.
- Pour stocker un projet i.e. le projet comme paquet : ptêt ben qu’oui, ptêt ben qu’non.
Faire un paquet R ?
🏄♂️ Surfer sur ses connaissances de développement (ou les rafraîchir),
🏄♂️ Surfer sur les outils existants (devtools & usethis).
“Research compendium.” Packaging Data Analytical Work Reproducibly Using R (and Friends), Ben Marwick, Carl Boettiger & Lincoln Mullen (2018), The American Statistician, 72:1, 80-88, DOI: <10.1080/00031305.2017.1375986>
Faire un paquet R ?
-
Les dépendances dans
DESCRIPTION, -
Les fonctions dans
R/avec documentation dansman/, -
Les données dans
data/(oudata-raw/), -
Les analyses comme vignettes (R Markdown),
-
Un README explicatif.
Projet comme paquet, outils spécifiques utiles
📦 rrtools de Ben Marwick fournit des instructions, modèles, fonctions pour faire un compendium basique adapté à la rédaction d’un article ou rapport reproductible avec R.
📦 holepunch de Karthik Ram permet de reproduire votre analyse sur un serveur Binder ! (🤫 marche aussi sans la structure de compendium)
🚀 R-universe par Jeroen Ooms à rOpenSci pour publier vos analyses.
Ne PAS structurer son projet comme un paquet
Project as an R package: An okay idea de Miles McBain.
Un peu une usine à gaz ? 🏭
“Ma réponse aux promoteurs du projet comme paquet: ==Vous gaspillez un temps précieux en faisant les mauvais paquets.==”
“Au lieu de faire rentrer votre travail dans le domaine du développement de paquet, avec la perte de fidélité induite, pourquoi ne faites-vous pas un paquet d’outils qui crée l’expérience fluide à la {devtools}/{usethis} pour votre domaine ?"
Comment structurer son projet
Comme on veut 😉 (comme votre équipe veut) mais
-
structure de base constante dans le temps ;
-
création automatisable.
Rendre la reproductibilité ✨ plus facile ✨.
Comment faire tourner le projet?

Picture by cottonbro on Pexels.
Faire tourner ça veut dire quoi ?
Comment allez-vous de vos scripts et données à vos résultats (rapport, figures) ?
🤸
Comment faire tourner le projet ?
Peut-être que cliquer sur le bouton tricot suffit ?
Mais peut-être pas, selon le cas ?
Discutons de deux cas
-
Optimiser une pipeline.
-
Garder les traces des différentes versions d’un rapport (entrées et sorties).
Discutons de deux cas
-
Optimiser une pipeline. 📦 targets maintenu par Will Landau.
-
Garder les traces des différentes versions d’un rapport (entrées et sorties). 📦 orderly maintenu par Rich FitzJohn.
targets de Will Landau
-
targets déduit les relations entre les morceaux de vos projets (e.g. si les données brutes changent, il faut tour refaire) ;
-
targets ne fait que les calculs nécessaires.
Le paquet fait partie de la collection de rOpenSci. Successeur du paquet drake du même auteur.
targets
Au centre d’un projet targets, le script _targets.R.
-
On y charge les paquets;
-
On y charge les fonctions (
source()de scripts dansR/par exemple); -
On y définit les cibles !
Les cibles
list(
tar_target(
raw_data_file,
"data/raw_data.csv",
format = "file"
),
tar_target(
raw_data,
read_csv(raw_data_file, col_types = cols())
),
tar_target(
data,
raw_data %>%
filter(!is.na(Ozone))
),
tar_target(hist, create_plot(data)),
tar_target(fit, biglm(Ozone ~ Wind + Temp, data))
)
Les cibles
Beaucoup de flexibilité notamment et des cibles communes pratiques dans tarchetypes e.g. tarchetypes::tar_age().
Comment ça tourne
-
Pour construire,
targets::tar_make()(ettargets::tar_destroy()) -
Pour comprendre sa pipeline,
targets::tar_glimpse()&co.
Visualisation de pipeline
targets::tar_glimpse()
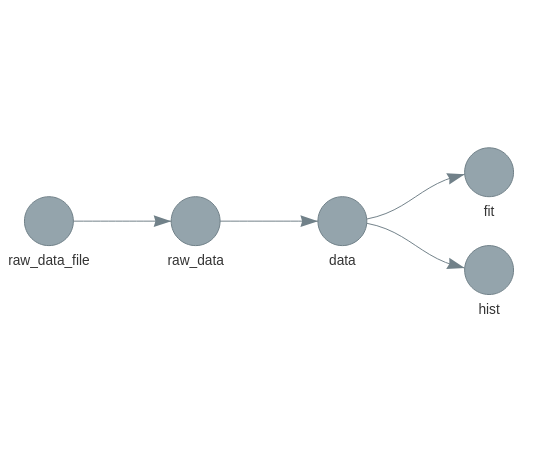
Illustration du manuel de targets.
Comment se mettre à targets ?
-
Le manuel !
-
Reproducible Computation at Scale in R with {targets} (Will Landau au RUG Lille).
-
Commencer avec un petit projet (mon niveau actuel 😅).
The R Targetopia
An R package ecosystem for democratized reproducible pipelines at scale
Comment suivre l’évolution de targets ?
-
Suivre le dépôt de targets ;
-
Suivre Will Landau ;
-
S’abonner à la lettre d’informations de rOpenSci ;
-
Trouver un groupes d’autres utilisateurs·rices. 😉
orderly de Rich FitzJohn
(Merci à Rich d’avoir répondu à mes questions 🙏)
Pour un problème différent : garder la trace de tout ce qui entre et sort d’une analyse à différents points.
Par exemple pour permettre de futurs audits.
L’analyse peut être énorme donc git pas adapté.
orderly
Dans orderly on a des repos (dépôts) et dans les repos on définit des reports (rapports).
Exemple avec un dépôt d’un rapport. orderly::orderly_init("blop") et orderly::orderly_new("example", "blop"), modification de fichiers.
blop
├── orderly_config.yml
└── src
└── example
├── orderly.yml
└── script.R
Configuration src/example/orderly.yml
script: script.R
artefacts:
- staticgraph:
description: A graph of things
filenames: mygraph.png
- data:
description: Data that went into the plot
filenames: mydata.csv
Script exemple
dat <- data.frame(x = 1:10, y = runif(10))
write.csv(dat, "mydata.csv", row.names = FALSE)
png("mygraph.png")
plot(dat)
dev.off()
Comment ça tourne ?
- On expérimente avec le “mode développement”.
- On fait une version brouillon.
id <- orderly::orderly_run("example", root = "blop")
Elle (resources, script, résultats, tout quoi !) apparaît dans le dossier draft/example/id-illisible.
- Si on est content on la “commit.”
orderly::orderly_commit(id, root = "blop")
Elle (resources, script, résultats, tout quoi !) apparaît dans le dossier archive/example/id-illisible.
Comment ça tourne ?
⚠️ Les dossiers archive et draft peuvent être énormes, à vous de les sauvegarder pas avec git. ⚠️
Comment se mettre à orderly ?
-
Le site de documentation d’orderly est vraiment top !
-
Commencer petit pour bien comprendre (encore une fois, mon niveau 👋).
Comment suivre l’évolution d’orderly ?
-
Suivre le dépôt d’orderly ;
-
Suivre le blog de l’équipe qui développe orderly ;
-
Suivre Rich FitzJohn sur Twitter.
Comment faire tourner le projet…
Conclusion

Picture by cottonbro on Pexels.
Merci
Avant de résumer, merci à l’équipe d’organisation et de programmation des rencontres R 2021, et à vous tou·te·s ! 🙏 ✨
Merci beaucoup à Christophe Dervieux pour ses remarques pertinentes sur le contenu de cette présentation !
Que faire pour bien dessiner un projet ?
🌻 Bons principes de base comme isolation du projet, sauvegardes.
🌻 Encapsulage du projet. (renv ? Docker ?)
🌻 Structure pratique, plutôt constante, automatisable. (paquet ou pas ?)
🌻 Outils de construction adaptés (bouton tricot ? targets ? orderly ?)
Où apprendre à bien dessiner des projets ?
Exemples de références truffées d’éléments utiles :
-
Cours “Reproducible Research Data and Project Management in R” d’Anna Krystalli.
-
Guide “Organisation d’un projet collaboratif de publication PROPRE” de Sébastien Rochette.
-
Good enough practices in scientific computing Wilson G, Bryan J, Cranston K, Kitzes J, Nederbragt L, et al. (2017) Good enough practices in scientific computing. PLOS Computational Biology 13(6): e1005510. https://doi.org/10.1371/journal.pcbi.1005510
-
The Turing Way, an open source community-driven guide to reproducible, ethical, inclusive and collaborative data science.
Que faire pour bien dessiner un projet ?
🌹 Lire toute l’oeuvre de Jenny Bryan.
🌹 Choisir ou même créer (en équipe) la boîte dans laquelle on met et construit le projet.
🌹 Ne pas avoir peur de changer d’outils au fil du temps.
Diapos 🔗 https://rr2021.netlify.app/